
Every team claims they have an incident process until something actually goes wrong.
Imagine a cloud service goes down at 2 AM, a customer reports unusual activity in their account, or a vendor informs you about a data breach. Suddenly, your Slack channels are flooded with messages, your CEO is asking questions, and no one can agree on who is responsible for what in that moment.
That moment reveals the hard truth. A shared doc or a rough checklist is not a real incident management policy, and only 55% of companies have a fully documented one.
In 2026, the cost of being unprepared is just as stark: the average U.S. data breach now costs $10.22 million.
So, this guide covers what an incident management policy is, how it differs from a response plan, what it must include, and how to write one.
We have also included a free template to help your team handle incidents confidently.
Here’s the quick version before we get into the details.
With the key points in place, let’s now break things down further.
If you want to see how we help teams build policies without the manual chaos, book a demo, and we will walk you through it.
What is an incident management policy?
An incident management policy is the governance document that defines how your organisation,
- prepares for
- identifies
- reports
- classifies
- escalates
- responds to
- recovers from and
- learns from incidents
It sets the rules and assigns authority. It also draws the boundary between "someone should look at this" and "we activate the response team now."
Think of the incident management policy as the foundation layer. Everything else sits on top of it. Without this foundation, your teams improvise every time something breaks.
Who uses an incident management policy?
It is used across more teams than most founders expect. Security, IT, operations, legal, and leadership all rely on it.
Modern organisations also use it to manage third-party incidents, supply chain disruptions, and insider threats. Any event that could affect your systems, data, customers, or business operations falls under its scope.
What types of incidents does it cover?
An information security incident management policy typically covers security events like unauthorised access, data breaches, and malware.
The scope can also extend to service outages, compliance failures, physical security events, and vendor-caused disruptions, depending on your risk profile.
The exact types of incidents your policy covers should reflect your actual attack surface.

A SaaS company faces different risks than a healthcare provider. Your policy should name the categories relevant to your environment.
Why does this document exist?
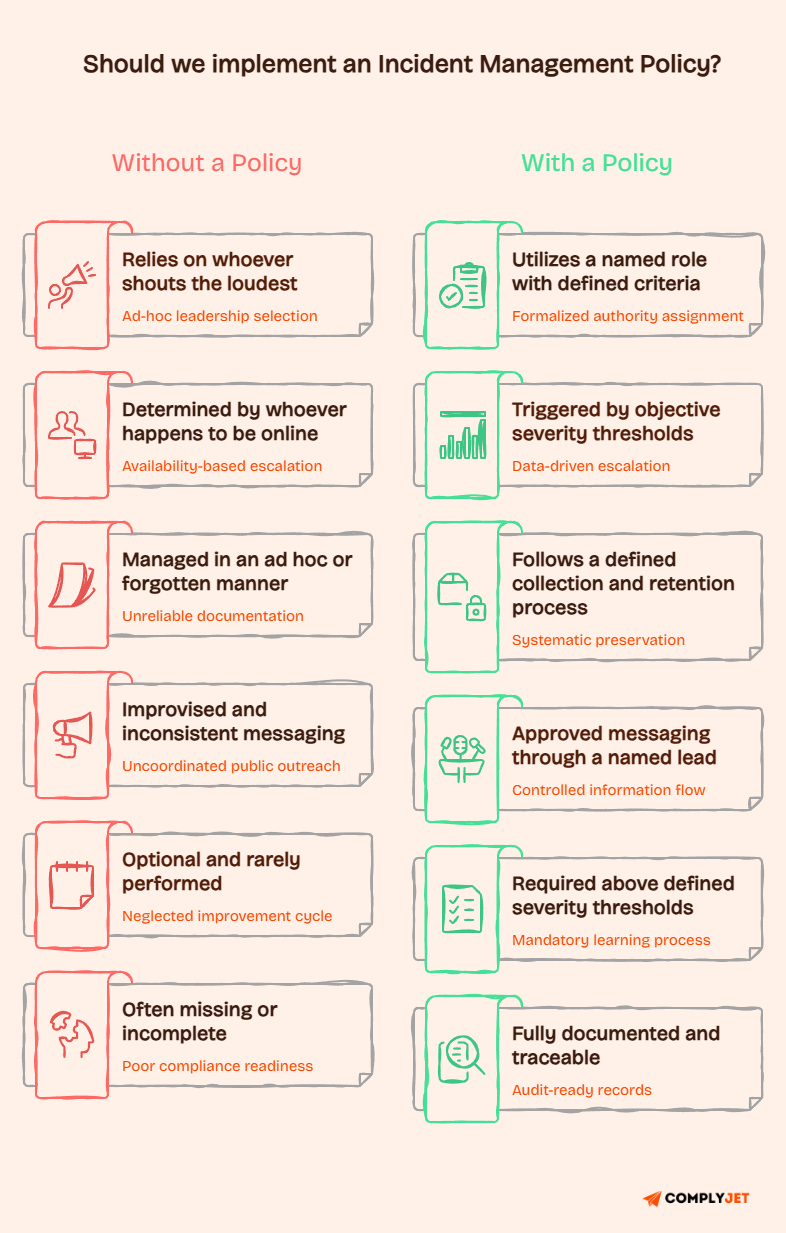
Without a policy, incident response becomes personality-driven. The loudest person decides what counts as a crisis. The most senior engineer online makes the escalation call.
That will definitely create chaos and accountability gaps.
A well-written security incident management policy removes the ambiguity. It defines
- What counts as an incident?
- Who owns the response?
- What gets documented?
- What happens after recovery?
For compliance purposes, NIST SP 800-61r3 frames incident response as part of broader cybersecurity risk management, not a standalone emergency protocol.
Once you understand the policy, the next question is how it differs from the other documents in your security program.
Incident management policy vs incident response policy vs procedure vs plan
These four terms get used interchangeably. They should not. Each document serves a different purpose at a different level of detail.
Blurring them is one of the most common reasons incident programs fall apart under pressure.
The fastest way to think about it: policy sets direction, procedure gives instructions, and a plan coordinates everything when an actual incident is running.
What is an incident management policy document?
The policy is the governance layer. It defines scope, authority, roles, principles, and expectations. It answers: what counts as an incident, who is accountable, what must be reported, and what standards apply. It does not explain how to contain a ransomware attack step by step.
A security incident response policy operates at the same level. The difference between the two is mostly framing. Some organisations use both. Most combine them into one governance document.
What is an incident response procedure?
A procedure is the execution layer. It gives your team specific actions for specific scenarios. A CISA incident response playbook standardises step-by-step actions to identify, contain, remediate, recover, and track mitigations. Incident management policy and procedure are both necessary. Combining them into one document creates a bloated file nobody reads during a real incident.
What is an incident response plan?
An incident response plan is the coordination framework. It defines who activates the team, how communication flows, and how decisions get made when things move fast.
CISA describes the plan as covering roles, responsibilities, key activities, and contact lists. An incident management process document maps the end-to-end lifecycle at a broader operational level, sitting between the policy and detailed playbooks.

Now, let’s see why this is a requirement.
Why every organisation needs an incident management policy?
A written incident management policy stops your incident response from becoming a series of improvised decisions made by whoever is available. Without it, teams argue about severity, escalation gets delayed, evidence disappears, and customers get inconsistent updates.
The same mistakes repeat after every event.

Faster escalation and clearer accountability
When an incident hits, the first ten minutes matter most. A clear policy defines who gets notified and when.
Nobody has to wonder whether to wake up the CISO at midnight.
Your policy names who owns triage, who owns communication, and who has the authority to declare a major incident. Without those assignments in writing, accountability drifts to whoever speaks up first.
Protecting sensitive information and business operations
A data breach or service outage can expose sensitive information. It will also trigger regulatory obligations and damage customer trust quickly.
This is where having an incident management policy helps. It gives the response team a defined path and creates a documented record.
Regulators, customers, and auditors will want to know what you did and when. Clear reporting requirements make that documentation easier to produce.
Third-party and supply chain incident coverage
Many serious incidents originate outside your walls.
A vendor gets breached. A cloud provider goes down. A third-party integration exposes your data.
A strong security incident management policy addresses third-party events explicitly. It defines what constitutes a reportable incident, when a vendor is involved, who coordinates the response, and what notification obligations apply.
Also read: Third-Party Risk Management Policy Guide
Supporting business continuity and lessons learned
When post-incident review is a policy obligation rather than a suggestion, your team actually runs them.
Those reviews feed lessons back into your controls, training, and processes. Business continuity and disaster recovery planning both depend on what your incident program learns over time.
A policy that ends at "recover the system" misses the long-term value.
Understanding the value of the policy is one thing. Knowing exactly what to put in it is where most teams get stuck. The next section covers every element your policy should include.
What should an incident management policy include?
A good (IMP) incident management policy is specific and not long. Every section should answer a real operational question your team might face during an active event.
The sections below represent what a complete, audit-ready IMP covers.
Curious what audit-ready looks like in practice? Real users share their experience on G2.
1. Purpose
The purpose section states the organisational intent in one or two sentences. Something like: this policy establishes how we identify, report, manage, and learn from incidents affecting our systems, data, and operations. Avoid filler language. State the actual goal.
2. Scope
Scope defines what the policy applies to. Name your systems, data types, teams, locations, and third-party relationships. Also state what is excluded. A vague scope is a common policy failure. "All IT systems" is not specific enough. Name the categories of systems, data types, and entities, including contractors and vendors.
3. Definitions
Definitions prevent arguments during a live incident. Terms like incident, event, problem, and major incident mean different things to different teams. Define each clearly. This section also sets the baseline for severity classification. Defining what constitutes a P1 incident here means your team is not debating it at 3 AM.
4. Roles and responsibilities
Every policy must name the people or roles accountable for each part of the incident lifecycle. This includes who owns triage, who escalates to leadership, who manages external communications, and who leads post-incident review. The incident commander role deserves specific attention. Without it defined, response teams stall waiting for direction.
5. Incident categories
Your policy should classify the types of incidents your organisation handles. Categories might include:
- Security incidents such as unauthorised access, data breaches, and malware infections
- Service incidents such as outages, degraded performance, and failed deployments
- Compliance incidents such as regulatory violations or data handling failures
- Physical incidents such as unauthorised facility access or hardware theft
- Third-party incidents such as vendor breaches or supply chain disruptions
Categories are not the same as severity. An incident can be a security incident at a P2 severity level. Both dimensions should exist in your policy.
6. Severity levels
Severity levels define how serious an incident is and what response actions are triggered. The most common model uses P1 through P4, where P1 is the most critical. Each level should map to a response time expectation and an escalation path. The policy should state how severity is assigned and who has the authority to change it. We cover the full P1 to P4 breakdown in its own section below.
7. Reporting requirements
Reporting rules tell your team what gets reported, to whom, and within what timeframe.
For public companies, the SEC cybersecurity disclosure rules require material incidents to be disclosed on a defined timeline.
For critical infrastructure organisations, CISA's CIRCIA rulemaking is moving toward a 72-hour reporting window for certain cyber incidents.
Your policy should reflect the obligations that apply to your organisation, so your team is never left guessing when the clock starts.
8. Escalation rules
Escalation rules define the path an incident takes as it grows. At what point does the security analyst escalate to the CISO? At what point does the CISO escalate to the board?
Write escalation rules for both time-based and severity-based triggers. A P2 incident uncontained after four hours may need P1 treatment.
9. Communication
Your policy must state who communicates externally during an incident, what they are authorised to say, and how messaging gets approved.
This applies to customer notifications, press inquiries, and regulatory filings. Internal communication rules matter equally. Who updates leadership, and how often, is important. Poor internal communication during an incident often creates more damage than the incident itself.
10. Evidence handling
Digital forensics and evidence handling are easy to overlook until they matter in a legal or regulatory context.
Your policy should define how logs, system images, and artefacts are preserved from the moment an incident is declared.
Improper handling can compromise investigations and create liability that outlasts the incident itself. NIST IR 8428 is a practical external reference worth pointing your team to for this section.
11. Recovery expectations
Recovery expectations define what "resolved" means. Is it when the system is back online? When the root cause is confirmed? When is a patch deployed? Define recovery criteria, so your team knows when an incident is officially closed and what sign-off is required before closure.
12. Post-incident review
Post-incident review is one of the most valuable parts of incident management and one of the most skipped. Require it for all incidents above a defined severity threshold.
The review should capture what happened, the root cause, what worked, what did not, and what changes will be made.
NIST states that lessons learned and root cause analysis improve cybersecurity risk management and help organisations prepare better for future incidents.
13. Policy ownership and review cycle
Every policy needs an owner and a review schedule. Annual review is standard. Quarterly is better for fast-moving organisations. State what triggers an out-of-cycle review. A major incident, a significant technology change, or a new regulatory requirement should all prompt an update.
14. Related documents
List the other documents your policy connects to. That includes your incident response procedure, incident response plan, business continuity plan, disaster recovery plan, and data breach notification policy. Include where those documents live and who owns them.
This helps your team navigate quickly and helps auditors understand your broader program.

With the content covered, understanding how the actual incident management process works in practice makes the policy much easier to write and use.
How does the incident management process work in practice?
The incident management process is the operational reality that your policy governs.
Think of it this way: the policy sets the rules, and the process is how those rules play out when something actually goes wrong.
Understanding the lifecycle is what helps you write a policy that supports your team in the moment rather than getting in the way of it.
Detection and triage
Every incident starts with detection. Something triggers an alert, a customer reports an issue, or a monitoring system flags an anomaly.
Triage is the validation step. Your team confirms the event is real, rules out false positives, and gathers enough information to classify it.
Your policy supports this by defining what counts as an incident and who is authorised to declare one.
Classification and prioritisation
Once confirmed, the incident gets classified by type and prioritised by severity. Both decisions shape what happens next.
NIST SP 800-61r3 explicitly connects detection and response to managing and prioritising incidents.
Your policy should establish the criteria used for both decisions so classification stays consistent across events and teams.
Escalation
Escalation moves the incident to the right people at the right time.
A P3 might stay within the security team. A P1 might require the incident commander, legal, communications, and executive leadership within minutes.
Escalation failures happen when the criteria are unclear or when there is no named escalation path in the policy.
The policy should make escalation straightforward enough to follow at 2 AM under pressure.
Containment and recovery
Containment limits the damage while recovery restores normal operations, and in complex security incidents, the two often run in parallel.
Mature security teams track both through mean time to contain and mean time to recover, because the numbers tell you how well your process is actually working.
That is exactly why your policy should require containment and recovery steps to be documented during every incident. Without that record, you lose the data that drives future improvement.
Post-incident review
Post-incident review is where your program actually improves. Changes to controls, detection rules, escalation paths, or training can all emerge from a thorough review. If your policy does not require this step, it will not happen consistently.

With the process clear, understanding how to classify incidents by severity gives you the operational specificity that makes a policy genuinely useful.
How should teams define P1, P2, P3, and P4 incidents?
Severity levels are one of the most practical parts of any IMP. Without them, every incident feels like a potential emergency.
The P1 to P4 model is widely used across IT and security teams.

Exact thresholds vary, but the framework is consistent enough that your policy can establish the logic even if specific SLA numbers live in a separate procedure.
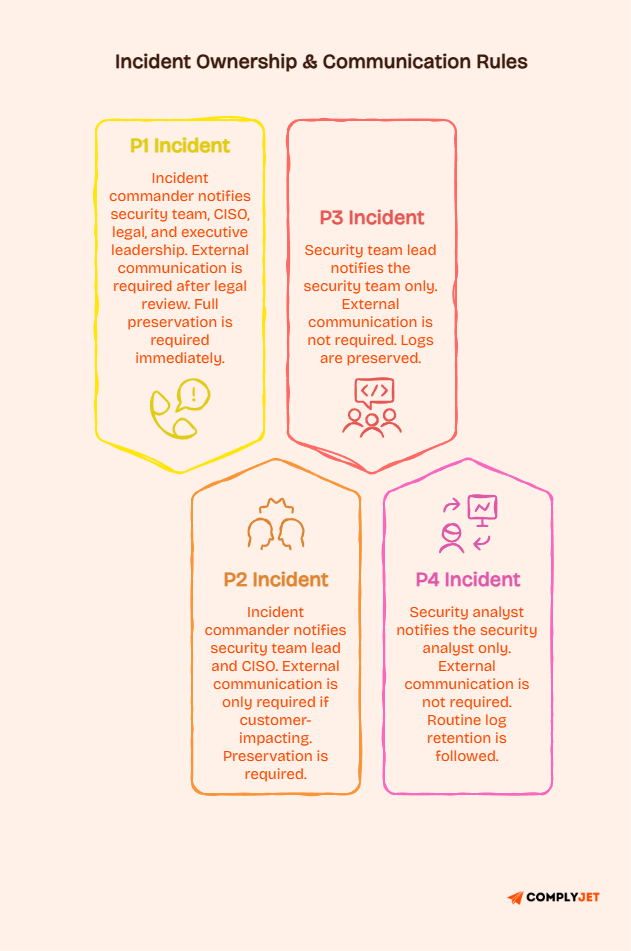
What P1 and P2 incidents look like
A P1 incident is your most critical severity level. It typically involves a confirmed data breach, a complete service outage affecting all customers, a ransomware infection, or any event that triggers immediate regulatory or legal obligations.
P1 incidents require immediate escalation to the incident commander and executive leadership.
A P2 incident is serious but slightly below critical. Examples include significant service degradation affecting a large portion of users, a suspected unauthorised access event, or a third-party breach affecting your data.
P2 incidents require urgent response but may allow slightly more coordination time before full escalation.
What P3 and P4 incidents look like
A P3 incident is moderate in impact. It might be a failed deployment affecting a small subset of users or an internal policy violation needing investigation.
Response is required, but the timeline is less urgent.
A P4 incident is low priority. It covers minor anomalies or small operational issues with workarounds available. These are addressed within normal business hours.
They still go through the incident process because documentation and trending matter even at low severity.
Read: Change Management Policy: Comprehensive Guide + Free Template (2026)
How severity affects communication and ownership
Severity determines who owns the incident, who gets notified, what communication goes external, and what evidence is preserved.
A P1 incident likely involves legal review before any external communication. A P4 may never leave the security team. Your policy should map severity levels to specific actions and owners.
That mapping turns severity levels from labels into operational instructions.
Why exact thresholds vary by organisation
There is no universal P1 definition. A P1 for a hospital involves different criteria than a P1 for an e-commerce startup.
Your severity model should reflect your actual risk profile, customer obligations, and regulatory environment. Inconsistent severity classification is one of the main failure points in incident response.
If two analysts classify the same event differently, your escalation and response will be inconsistent as well.
With severity levels covered, the natural next step is walking through how to actually write this document from scratch.
How to write an incident management policy step by step
Writing an IMP is about precision, not length. Every section should answer: what does my team need to know during an actual incident?
1. Define purpose and scope.
Start with one or two sentences explaining why this policy exists. Then define the scope precisely. Name the systems, data categories, teams, locations, and third parties covered.
"All systems" is not useful. "All production systems, customer-facing applications, and data handling, personal, financial, and health records" is useful.
Specificity prevents argument later.
2. Identify systems, data, and teams covered.
Walk through your actual technology environment. List the systems that could be involved in an incident.
Note which data types those systems handle.
Identify the teams that touch those systems. This inventory feeds directly into your roles and responsibilities section and prevents guesswork that leads to gaps.
3. Define incident types and severity.
Use the categories and P1 to P4 model described earlier. Write clear criteria for each severity level. Include examples where possible.
Your definitions should be written by people who have responded to real incidents. They will know what questions come up during triage.
Those questions should be answered here before they arise in practice.
4. Assign roles and escalation ownership.
Name the roles that own each part of the incident lifecycle.
Assign a primary and backup for each role. Define the escalation path from the first responder to the executive level.
A policy that says "the security team will respond" is not operational.
A policy that says "the on-call security analyst owns triage, escalates to the CISO at P2 and above, and notifies legal for any P1 event" is.
5. Add reporting and communication expectations.
Define internal reporting requirements alongside external reporting obligations, and make clear which roles are authorised to communicate externally and what approval process applies before anything goes out.
Your information security incident management policy should also spell out the regulatory timeframes that apply to your organisation.
Under CIRCIA, certain organisations must report qualifying incidents within 72 hours.
Under GDPR, personal data breaches carry the same 72-hour window from the moment you become aware of them.
For more clarity, read: 10 Must-Have GDPR Compliance Requirements for Businesses in 2026
6. Connect the policy to procedures and plans.
Your policy should name the procedures, plans, and playbooks beneath it without including their content. Reference them clearly so team members know where to go for detailed execution guidance.
When an auditor asks how you manage incidents, you can show the policy as the governance layer and point to the procedures as the execution layer.
That separation demonstrates program maturity.
7. Review, approve, train, and test.
A policy without leadership approval is advisory at best. Get a formal sign-off with a record of who approved it and when.
Schedule training for all teams in scope.
Test the policy by running a tabletop exercise. CISA recommends regularly testing your incident management capabilities. Gaps surface during exercises, not during production incidents.

Read: Security Awareness Training Policy: Guide + Free Template (2026)
With the writing process covered, the template section gives you a ready starting point, so you are not building this from a blank page.
Free incident management policy template
An incident management policy template gives you a structured starting point.
It saves time and ensures you do not miss key sections.
A template is not a finished document. It is a skeleton your team fills in with real, organisation-specific content. The risk of a template is blind copying.
A policy copied without customisation will cover sections that do not apply and miss details that are critical for your environment.
What the template covers
A solid incident management policy template includes these components:
- Policy purpose and objectives
- Scope definition, including systems, data, and teams
- Glossary of key terms
- Incident categories and severity levels
- Roles and responsibilities matrix
- Reporting requirements and timeframes
- Escalation paths
- Communication guidelines
- Evidence handling rules
- Recovery criteria
- Post-incident review requirements
- Policy ownership and review schedule
- References to related documents
These components map directly to the checklist covered earlier.
Our compliance documentation guide explains how to structure these components for different audit frameworks.
Who should use this template?
The template is most useful for teams writing their first formal incident management policy, teams replacing a weak or outdated policy, and teams preparing for ISO 27001, SOC 2, or similar compliance audits.
How to customise it
Read the entire template before editing. Understand what each section asks for.
Replace placeholder language with your actual systems, team names, escalation paths, and review schedules. Delete sections that do not apply. If you operate in healthcare, add your HIPAA-specific reporting obligations explicitly.
The template should bend to your reality.
What formats work best
For internal use and ongoing updates, a Word or Google Doc format works best.
For formal distribution and archiving, a PDF is cleaner and harder to accidentally modify. For audit purposes, keep a version history. When an auditor asks when your policy was last reviewed, you should be able to show the previous version alongside the current one.
If you want a template that is already mapped to ISO 27001 and SOC 2 controls, see how our customers manage their policy libraries without building everything from scratch.
With the template approach covered, seeing what real policy language looks like makes the process more concrete.
Incident management policy example
The sections below show how real policy clauses might read in a finished document. These are short illustrative examples, not complete policy text. The goal is to show you the level of specificity that makes a policy operational.
Sample purpose clause
This policy establishes the framework for managing incidents that affect the confidentiality, integrity, or availability of our systems, data, or business operations. It defines reporting obligations, response ownership, severity classification, and post-incident review requirements for all teams within scope.
Clear. Specific. No filler. If your purpose clause runs longer than two sentences, it is covering scope or definitions that belong in their own sections.
Sample scope clause
This policy applies to all employees, contractors, and third-party service providers who access or operate our production systems, customer data environments, or internal infrastructure. It covers all incidents involving personal data, financial data, and business-critical applications, regardless of where those systems are hosted.
Note what this clause does. It names who is covered, what data is in scope, and clarifies that cloud-hosted systems are included. Clarity on cloud coverage is especially important for modern teams.
Sample severity section
Incidents are classified P1 through P4.
- P1 incidents involve confirmed data breach, full service outage, or regulatory trigger and require immediate escalation to the incident commander and executive leadership.
- P2 incidents involve significant service degradation or suspected unauthorised access and require response initiation within one hour.
- P3 incidents are moderate and require a response within four hours during business hours.
- P4 incidents are low impact and are addressed within normal operational workflows within one business day. Severity may be reclassified as new information becomes available.
Sample reporting and escalation clause
All confirmed incidents must be reported to the security team within 30 minutes of identification. P1 and P2 incidents require notification of the CISO and legal counsel within one hour. External reporting to regulators or customers requires written approval from the CISO or designated communications lead before any disclosure.
Short enough to remember. Specific enough to follow.
Sample review and lessons learned clause.
A post-incident review is required for all P1 and P2 incidents and for any P3 incident that reveals a systemic control failure. The review must be completed within five business days of incident closure. Findings must be documented and assigned to an owner with a resolution timeline.
This clause makes review mandatory, sets a deadline, and requires ownership of follow-up actions. Those three elements make the difference between a review that happens and one that gets quietly skipped.
With examples in hand, the next step is understanding how to adapt this policy for different environments and team types.
How should you adapt the policy for IT, cloud, and security teams?
A generic incident management policy works as a starting point. But a policy adapted to your environment works much better. Adaptation is not about rewriting everything.
It is about ensuring the policy reflects your actual systems, real dependencies, and the incidents your teams actually face.

IT service incidents vs security incidents
IT incident management focuses on restoring service availability. The policy for IT-type incidents emphasises SLAs, on-call rotations, and service restoration timelines. Security incident management adds investigation and evidence preservation.
You first determine whether a system was compromised, what data may have been accessed, and whether forensic evidence needs preservation before recovery.
An IT incident management policy that conflates these two concerns creates serious risk during security events.
SaaS and cloud dependencies
Modern companies depend on external services. An outage at your cloud provider, CRM, or payment processor can cause a customer-impacting incident you did not cause and cannot directly fix.
Define what constitutes an incident when the root cause is a third-party SaaS provider. Assign someone to own vendor communication. Clarify what your team does while waiting for the vendor to resolve the issue.
Cloud incident management policy gaps show up badly during outages.
Customer-impacting incidents
Customer-facing incidents have a communication dimension that internal incidents do not. Your policy should define the threshold at which you notify affected customers, what that notification says, and who approves it.
Teams often focus on technical response and forget that customers need accurate, timely information. A policy that defines communication triggers and approval paths prevents inconsistent messaging that erodes trust.
ITIL-oriented environments
Some organisations use the ITIL framework for IT service management. If your team operates within an ITIL context, your IMP should align with ITIL terminology and process flows. ITIL separates incident management from problem management. Incident management restores service.
Problem management identifies the root cause. Using ITIL terms outside their defined meanings creates confusion during response.
With adaptation covered, the final section on compliance and audit readiness ties the policy back to the standards and frameworks that many teams are working toward.
How does an incident management policy support ISO 27001, NIST, and audit readiness?
Compliance frameworks do not always specify exact document titles. But the expectation of documented, operational incident management governance is present in every major security standard.
A well-written policy helps you satisfy those expectations with evidence that auditors can actually review.
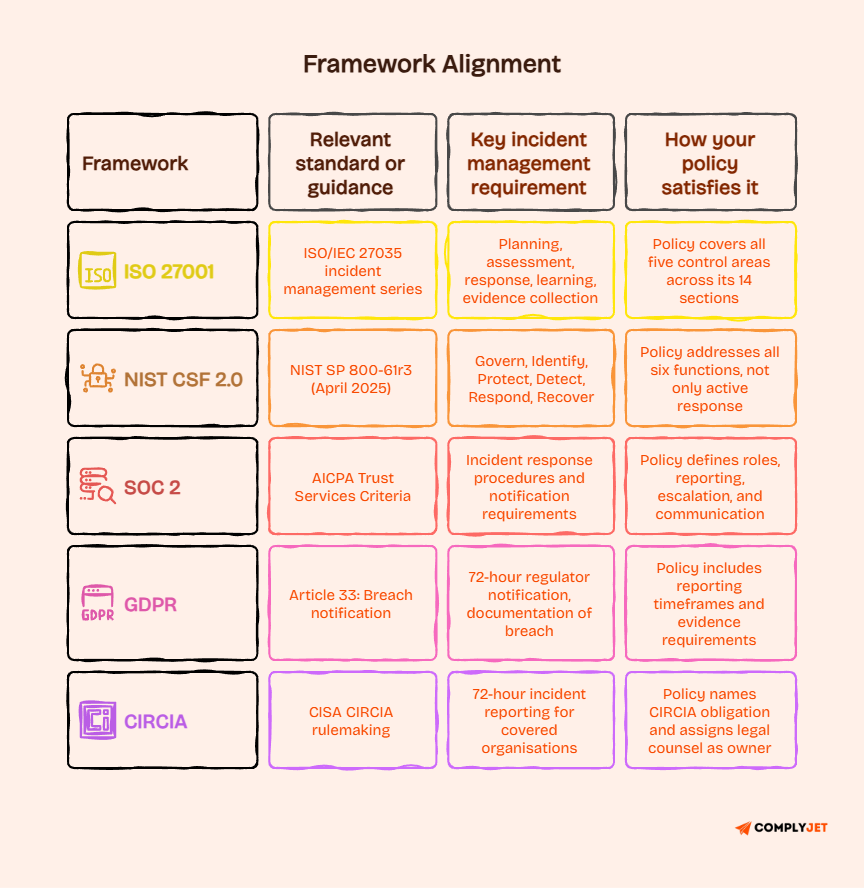
ISO 27001 incident management policy requirements
ISO/IEC 27035 is the international standard specifically covering information security incident management. It defines control areas including planning and preparation, assessment and decision, response, learning, and evidence collection.
ISO 27001 Annex A maps to these control expectations directly.
An ISO 27001 incident management policy should demonstrate that your organisation has defined the governance for each of those control areas and that the policy is reviewed regularly and approved by appropriate management.
NIST incident response alignment
NIST SP 800-61r3, finalised in April 2025, shifts incident response into part of cybersecurity risk management aligned with NIST Cybersecurity Framework 2.0. Your policy should connect to all six CSF 2.0 functions: Govern, Identify, Protect, Detect, Respond, and Recover. That means the policy covers prevention, readiness, and continuous improvement, not only active response.
Business continuity and disaster recovery connections
Your IMP should name its relationship with your business continuity plan and disaster recovery plan. A serious security incident can trigger BCP activation.
A major outage may require DR plan execution. Keeping these connections documented prevents teams from operating in silos during a complex event.
Review, testing, and evidence expectations
Compliance audits check whether your policy is current, approved, tested, and followed.
You need evidence of your policy review cycle, testing activities, and post-incident reviews. CISA is explicit that incident management plans should be tested through an established testing process.
Tabletop exercises, simulations, and real incident documentation all serve as evidence. Keep records of every exercise and review.

Once your policy is aligned with these frameworks, understanding the common failure patterns helps you avoid the gaps that most teams discover too late.
What common mistakes make incident management policies fail?
Most failed policies fail for predictable reasons, and document length is rarely one of them.
The real problem is that the policy lives in a folder nobody opens and is written for an auditor instead of the people actually responding at 2 AM.
It has no examples, no clear ownership, and no connection to how your team actually works when things go wrong.
Vague scope and no incident owner
A policy that covers "all systems and data" without naming specific environments is too vague to enforce. When an incident occurs, someone will argue that it falls outside the policy's intent.
A vague scope creates permission to ignore the policy. Equally damaging is the absence of an incident owner.
If no role is named as responsible for declaring, managing, and closing an incident, every responder operates with partial authority.
Policy tries to do too much or too little
A policy that includes 40-step response procedures is a procedure with a governance wrapper. The opposite problem is a policy that says, "incidents should be reported to the security team promptly." That is a principle, not a policy. The right level of detail sits between those extremes. Keep your incident response procedures separate from your governance layer and link them clearly.
No severity model and no communication path
A policy without severity levels treats every incident as equally urgent. That burns out your team and causes real P1 events to get lost in P3 noise. Communication paths are equally critical. When they are undefined, incident communication becomes improvised, and that inconsistency creates reputational and legal risk.
No evidence handling and no review cadence
If your policy does not mention how logs and system artefacts are preserved, your team has no obligation to handle evidence correctly. No review cadence means the policy slowly becomes irrelevant. A policy written two years ago without updates may no longer reflect how your team operates.
No mapping to real tools or incident response automation
A policy that references processes your tools do not support is difficult to follow. If your detection comes from a specific SIEM, your policy should acknowledge that.
If your incident response automation handles alert routing, your policy should align with how that system works.
When policy and tools are aligned, your team follows the policy naturally. When they are not, the policy gets read once and ignored.

Check how we help teams close this gap at our pricing page.
Frequently asked questions
What are the 5 stages of the incident management process?
The five stages are detection, triage and classification, containment, recovery, and post-incident review. Detection identifies that something has happened. Triage confirms it and assigns severity. Containment limits damage. Recovery restores normal operations. Post-incident review captures lessons and drives improvement. NIST's updated guidance from SP 800-61r3 emphasises that preparation and readiness are equally important stages in the lifecycle.
What are the 7 steps of incident response?
The seven steps are preparation, identification, containment, eradication, recovery, documentation, and lessons learned. Preparation happens before any incident. Identification confirms that one is occurring. Containment prevents it from spreading. Eradication removes the root cause. Recovery restores service. Documentation creates the audit trail. Lessons learned feed improvements back into the program.
What are the 4 phases of incident management?
The four phases are preparation, detection and analysis, containment and recovery, and post-incident activity. This model comes from earlier NIST guidance and remains widely used. Preparation is ongoing. Detection and analysis are triggered by events. Containment and recovery are active responses. Post-incident activity is reflective and corrective.
What are the benefits of an IRP?
An incident response policy gives your organisation consistent rules for handling unexpected events. It reduces decision-making time, creates accountability, and supports regulatory compliance. The less obvious benefit is cultural. A clear policy signals that incident management is taken seriously. People are more likely to flag potential incidents early when they know there is a clear, fair process for handling them.
What are the 5 key areas of incident management?
The five key areas are detection and reporting, classification and prioritisation, response and containment, recovery and restoration, and review and improvement. A mature incident management program performs all five consistently. Most organisations are weakest in review and improvement because it requires discipline after the immediate pressure has lifted.
What is incident management with an example?
Incident management is the end-to-end process of identifying, responding to, and learning from events that affect your systems, data, or operations.
A practical example: a customer reports accessing another user's account data. Your team classifies this as a P1 security incident. The incident commander is notified. The security team contains the exposure by revoking the affected sessions. Legal is notified. Root cause investigation reveals a flawed authorisation check in a recent deployment. A patch is deployed. A post-incident review identifies the testing gap that allowed the bug to reach production. That review leads to a change in your deployment checklist.
What are the major incident management principles?
The core principles are: incidents must be reported promptly, severity must be assessed consistently, response must be owned by named individuals, communications must be controlled and accurate, evidence must be preserved, recovery must be confirmed rather than assumed, and lessons must be documented and acted on.
What are the 5 W's in an incident report?
The five W's are who, what, when, where, and why. Who was involved and who discovered the incident? What systems, data, or services were affected? When the incident occurred and when it was detected. Where the incident originated. Why it happened, the root cause or contributing factors. An incident report answering all five gives your team, management, and auditors a complete picture.
Conclusion
An incident management policy should not be a static file written once for compliance and then forgotten. It should give your organisation a consistent way to classify incidents, assign ownership, escalate quickly, recover with discipline, and improve after each event.
Review your current policy against the checklist in this guide.
Check for gaps in severity levels, ownership assignments, communication paths, evidence handling requirements, and post-incident review obligations. If those elements are missing or vague, the policy is not ready for a real incident.
The goal is a document your team can actually use. Clear. Specific. Connected to real workflows and real tools. Reviewed regularly. Approved by leadership. Tested before you need it.
If your team is ready to build or update your incident management policy with a framework that supports real compliance and real operations, start your free trial and see how teams maintain audit-ready programs without the manual overhead.






